|
I am a tenure-track Assistant Professor at the School of Intelligence Science and Technology, Peking University, and an adjunct research scientist at Beijing Institute for General Artificial Intelligence. My colleagues and I hypothesize that there exists some fundamental representations or cognitive architectures underpinning the intelligent behaviors of humans. By uncovering and reproducing such an architecture, we hope to enable long-term human-robot shared autonomy by bridging
I received a Ph.D. in Computer Science and a M.S. in Mechanical Engineering from UCLA, working in the Center for Vision, Cognition, Learning, and Autonomy with Professor Song-Chun Zhu. My work at UCLA was supported by DARPA SIMPLEX, DARPA XAI, ONR MURI, and ONR Cognitive Robot. Before joining VCLA, I graduated with a B.S. in Mechanical Engineering and a B.S. in Computer Science with a Mathematics minor from Virginia Polytechnic Institute and State University (Virginia Tech) in 2016. CV / Google Scholar / X |

|
|
I'm interested in robot perception, planning, learning, human-robot interaction, and virtual and augmented reality. The five papers that best represent my work are highlighted. |

|
Xi Chen*, Yuan Gao*, Hangxin Liu, Fangkai Yang, Ali Ghadirzadeh, Jun Yang, Bin Liang, Chongjie Zhang, Tin Lun Lam, Song-Chun Zhu Science Robotics, 2026 Paper We introduce the Intention-Aligned Imitation Learning framework that extends the conventional scope of IL by enabling robots to reproduce motions demonstrated by heterogeneous peers, even in previously unseen situations. |
|
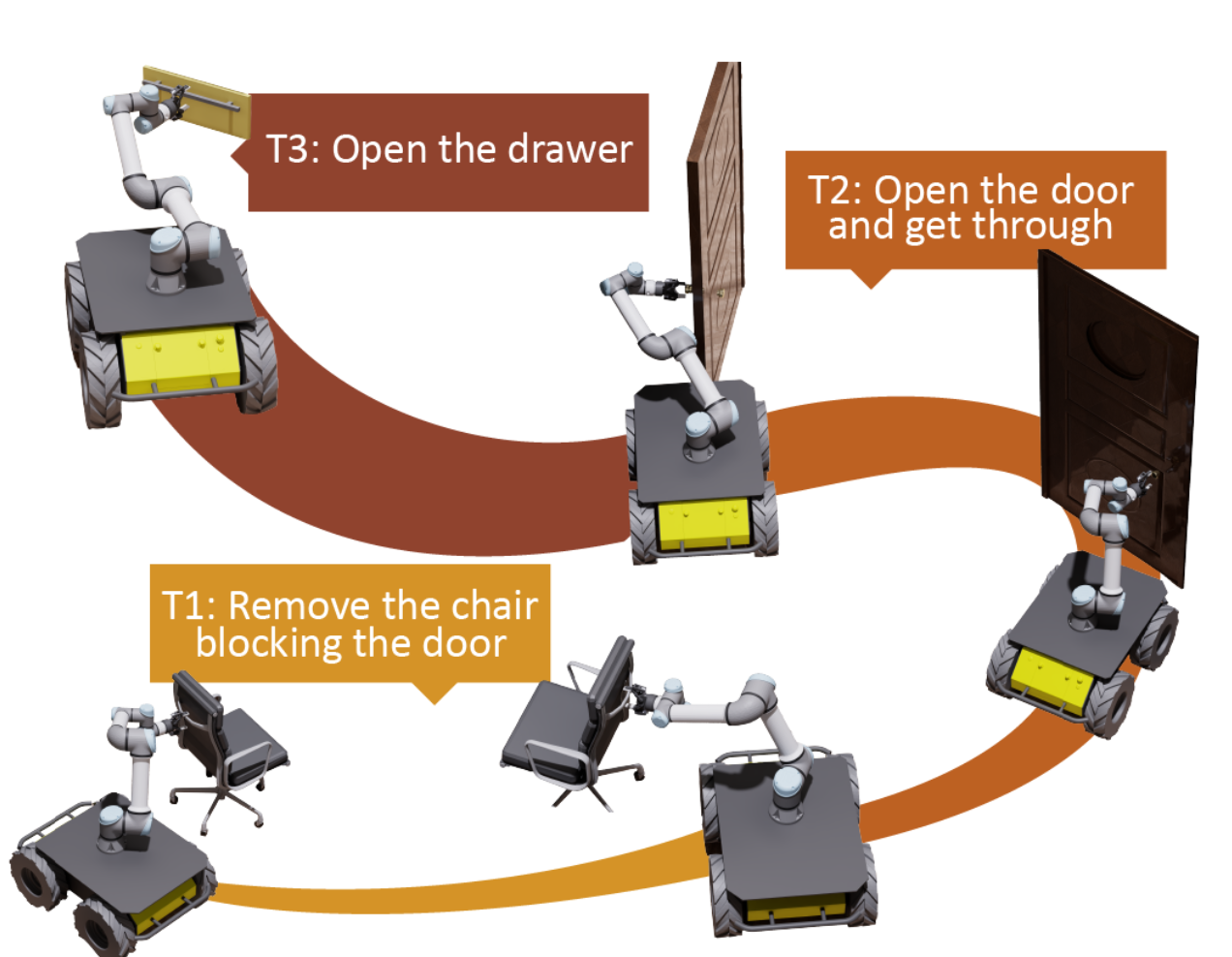
Ziyuan Jiao, Yida Niu, Zeyu Zhang, Yangyang Wu, Yao Su, Yixin Zhu, Hangxin Liu✉, Song-Chun Zhu IEEE Transactions on Robotics (T-RO), 2025 Paper / Video (bilibili) / Project Page We present a Sequential Mobile Manipulation Planning (SMMP) framework that can solve long-horizon multi-step mobile manipulation tasks with coordinated whole-body motion, even when interacting with articulated objects. |
|
Peiyao Hou*, Danning Sun*, Meng Wang, Yuzhe Huang, Zeyu Zhang, Hangxin Liu, Wanlin Li, Ziyuan Jiao IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025 Paper
|

|
Hongtao Li, Ziyuan Jiao, Xiaofeng Liu, Hangxin Liu, Zilong Zheng, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025 Paper
|
|
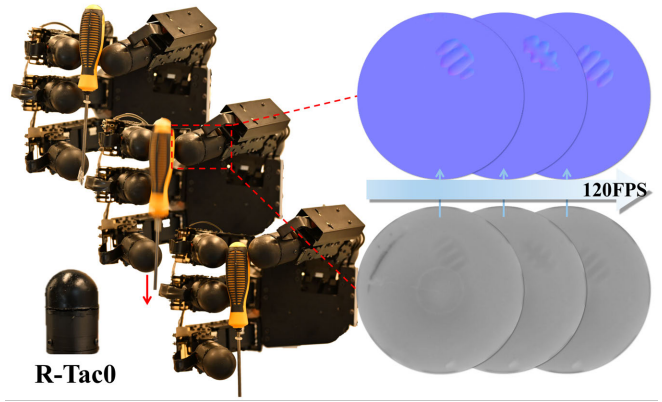
Wanlin Li*, Pei Lin*, Meng Wang*, Chenxi Xiao, Kaspar Althoefer, Yao Su, Ziyuan Jiao, Hangxin Liu IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025 Paper
|
|
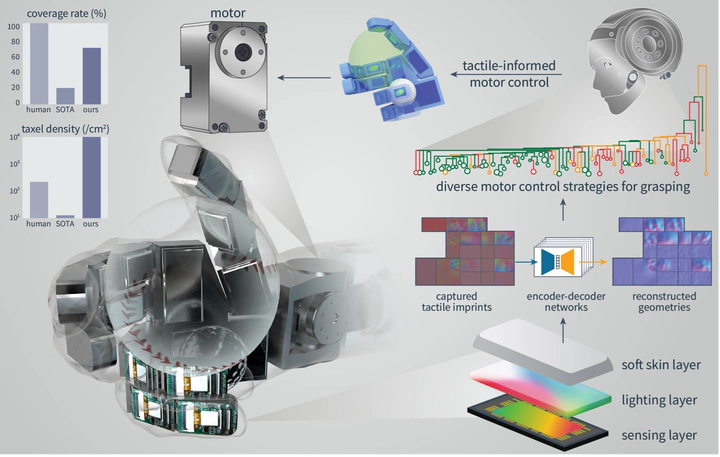
Zihang Zhao*, Wanlin Li*, Yuyang Li*, Tengyu Liu*, Boren Li, Meng Wang, Kai Du, Hangxin Liu✉, Yixin Zhu✉, Qining Wang, Kaspar Althoefer✉, Song-Chun Zhu * equal contributors nature machine intelligence, 2025 (Science Robotics Editors' Choice Adaptive humanlike grasping) Paper / Video (vimeo, bilibili) We present F-TAC Hand, a biomimetic hand featuring high-resolution tactile sensing across 70% of its surface area. The hand, powered by our generative algorithm that synthesizes human-like hand configurations, demonstrates robust grasping capabilities in dynamic real-world conditions. |

|
Zeyu Zhang*, Sixu Yan*, Muzhi Han, Zaijin Wang, Xinggang Wang, Song-Chun Zhu, Hangxin Liu✉ * equal contributors IEEE Robotics and Automation Letters (RA-L), 2025 Paper / Video (YouTube, bilibili) / Project Page M3Bench features 30,000 object rearrangement tasks across 119 diverse scenes, providing expert demonstrations generated by our newly developed M3BenchMaker, an automatic data generation tool that produces whole-body motion trajectories from high-level task instructions using only basic scene and robot information. |
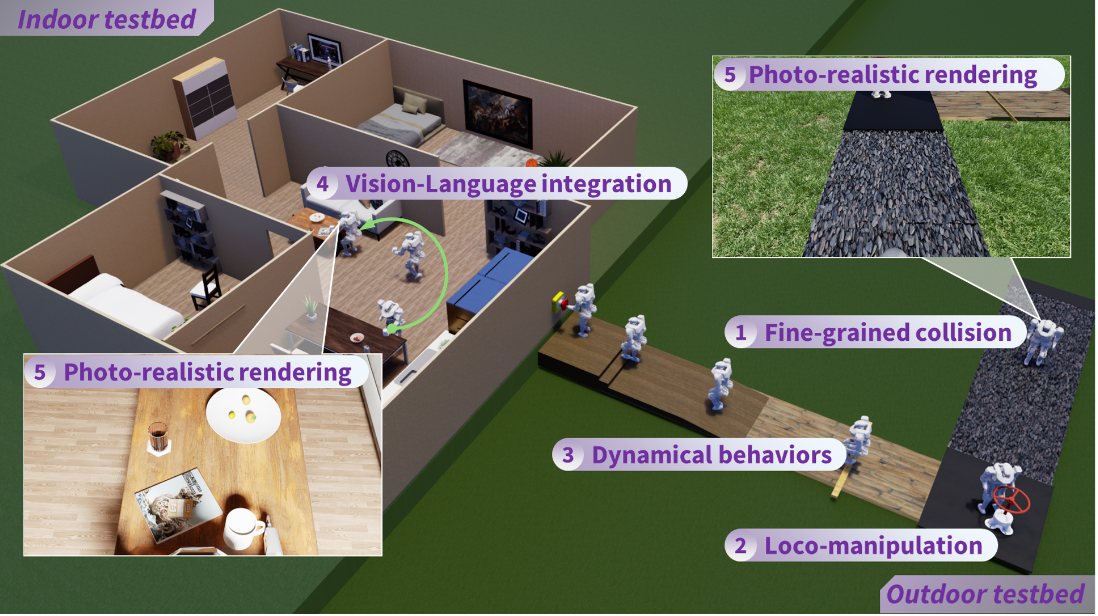
|
Hangxin Liu, Qi Xie, Zeyu Zhang, Tao Yuan, Song Wang, Zaijin Wang, Xiaokun Leng, Lining Sun, Jingwen Zhang, Zhicheng He, Yao Su Journal of Field Robotics, 2025 Paper / Video (YouTube) / Project Page A physics-realistic and photo-realistic humanoid robot testbed is developed to offer high-quality scene rendering and robot dynamic simulation, facilitating collaborative research between embodied AI. |

|
Sixu Yan, Zeyu Zhang, Muzhi Han, Zaijin Wang, Qi Xie, Zhitian Li, Zhehan Li, Hangxin Liu✉, Xinggang Wang✉, Song-Chun Zhu IEEE Transactions on Pattern Analysis and Machine Intelligence (IEEE TPAMI), 2025 Paper / Video (YouTube, bilibili) / Project Page We used previous VKC-based methods to generate high-quality mobile manipulation data for training a diffusion model which in turn helps trajectory optimization. |

|
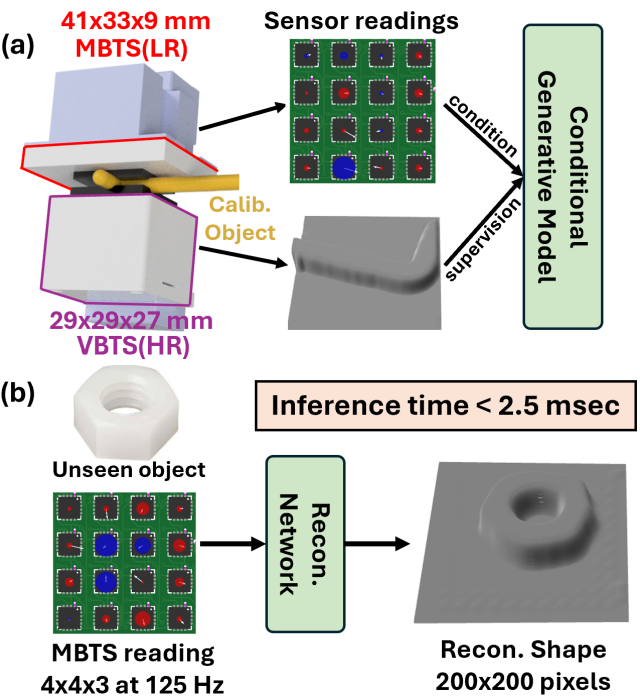
Meng Wang*, Wanlin Li*, Hao Liang, Boren Li, Kaspar Althoefer, Yao Su, Hangxin Liu * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024 Paper / Video (bilibili) We develop a synchronized image acquisition system with minimal latency, propose a modularized VBTS design for easy integration into finger phalanges, and devise a zero-shot calibration approach to improve data efficiency in the simultaneous calibration of multiple VBTSs. |
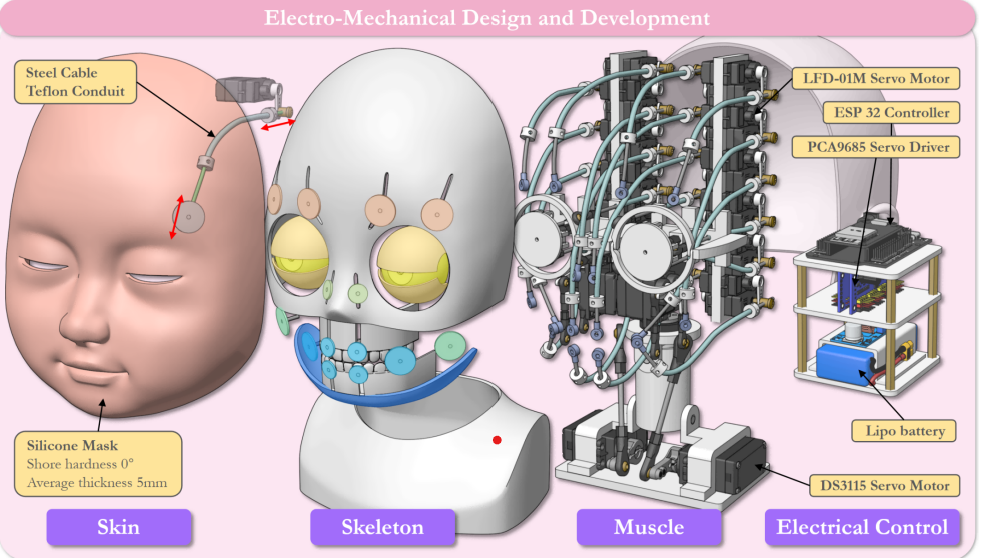
|
Boren Li*, Hang Li*, Hangxin Liu * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024 Paper / Video (bilibili) / Project Page This paper employs linear blend skinning (LBS) as a unifying representation to guide both embodiment design and motion synthesis, driving animatronic robot facial expressions from speech input. |
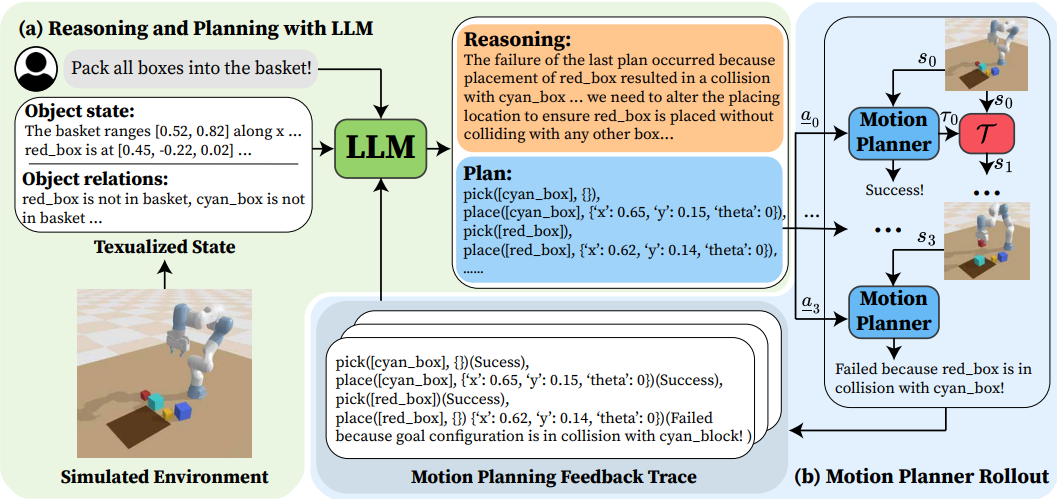
|
Shu Wang*, Muzhi Han*, Ziyuan Jiao*, Zeyu Zhang, Ying Nian Wu, Song-Chun Zhu, Hangxin Liu * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024 Paper We leverage the powerful reasoning and planning capabilities of pre-trained LLMs to propose symbolic action sequences and select continuous action parameters for motion planning. |
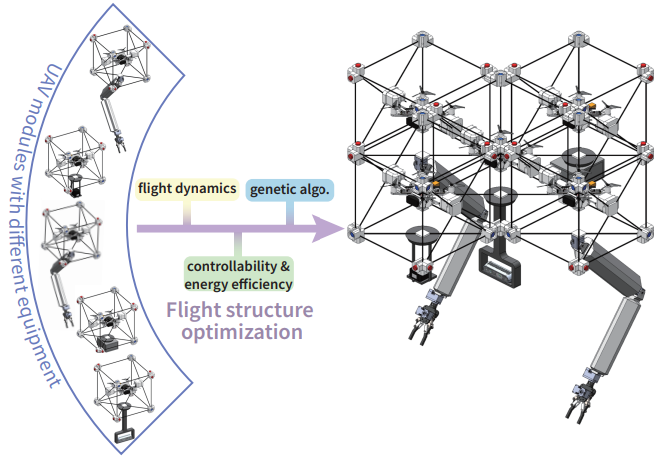
|
Yao Su, Ziyuan Jiao, Zeyu Zhang, Jingwen Zhang, Hang Li, Meng Wang, Hangxin Liu IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024 Paper This paper presents a Genetic Algorithm (GA) designed to reconfigure a large group of modular Unmanned Aerial Vehicles (UAVs), each with different weights and inertia parameters, into an over-actuated flight structure. |

|
Hangxin Liu*✉, Zeyu Zhang*, Ziyuan Jiao*, Zhenliang Zhang, Minchen Li, Chenfanfu Jiang, Yixin Zhu✉, Song-Chun Zhu * equal contributors Engineering, 2024 Paper / Video (YouTube, bilibili) / Project Page To endow embodied AI agents with a deeper understanding of hand-object interactions, we design a data glove that can be reconfigured to collect grasping data in three modes: (i) force exerted by hand using piezoresistive material, (ii) contact points by grasping stably in VR, and (iii) reconstruct both visual and physical effects during the manipulation by integrating physics-based simulation. |
|
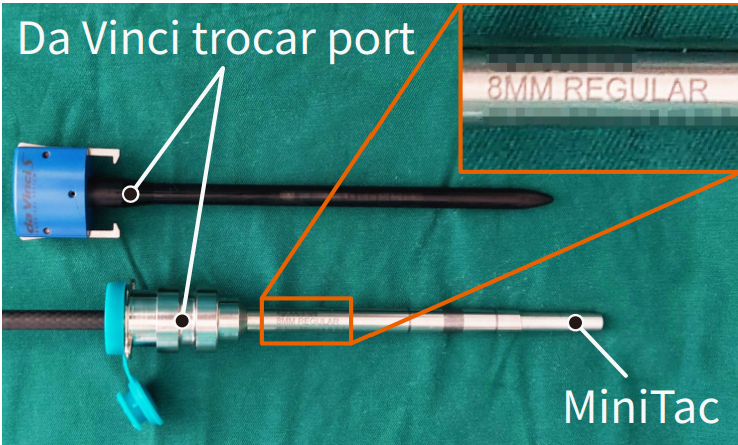
Wanlin Li*, Zihang Zhao*, Leiyao Cui*, Weiyi Zhang* Hangxin Liu, Li-An Li, Yixin Zhu * equal contributors IEEE Robotics and Automation Letters (RA-L), 2024 Paper We introduce MiniTac, a novel vision-based tactile sensor with an ultra-compact cross-sectional diameter of 8 mm, designed for seamless integration into mainstream RAMIS devices. |

|
Yao Su*, Jingwen Zhang*, Ziyuan Jiao, Hang Li, Meng Wang, Hangxin Liu * equal contributors IEEE International Conference on Robotics and Automation (ICRA), 2024 Paper / Video (bilibili) This paper presents an efficient method to plan motions that are consistent with the dynamics of over-actuated UAVs. |

|
Zhicheng He, Jiayang Wu, Jingwen Zhang, Shibowen Zhang, Yapeng Shi, Hangxin Liu, Lining Sun, Yao Su, Xiaokun Leng IEEE Robotics and Automation Letters (RA-L), 2024 Paper / Video (bilibili) This paper introduces a novel integrated dynamic planning and control framework, termed centroidal dynamics modelbased model predictive control (CDM-MPC), designed for robust jumping control that fully considers centroidal momentum and non-constant centroidal composite rigid body inertia. |
|
Zhenliang Zhang, Zeyu Zhang, Ziyuan Jiao, Yao Su, Hangxin Liu, Wei Wang, Song-Chun Zhu IEEE Conference on Virtual Reality and 3D User Interfaces (VR), 2024 Paper This research introduces a novel, highly precise, and learning-free approach to locomotion mode prediction, a technique with potential for broad applications in the field of lower-limb wearable robotics. |

|
Shunyi Zhao*, Zehuan Yu*, Zhaoyang Wang*, Hangxin Liu, Zhihao Zhou, Lecheng Ruan, Qining Wang * equal contributors IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2023 Paper In this paper, we introduce the symmetrical reality framework, which offers a unified representation encompassing various forms of physical-virtual amalgamations. |

|
Zeyu Zhang*, Lexing Zhang*, Zaijin Wang, Ziyuan Jiao, Muzhi Han, Yixin Zhu, Song-Chun Zhu, Hangxin Liu * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023 Paper / Video (YouTube, bilibili) / Project Page / Code We extend our work in IJCV22 and ICRA21 by segmenting the objects in the panoptic map into parts and replace those parts by primitive shapes, which results in more realistic functionally equivalent scenes. |
|
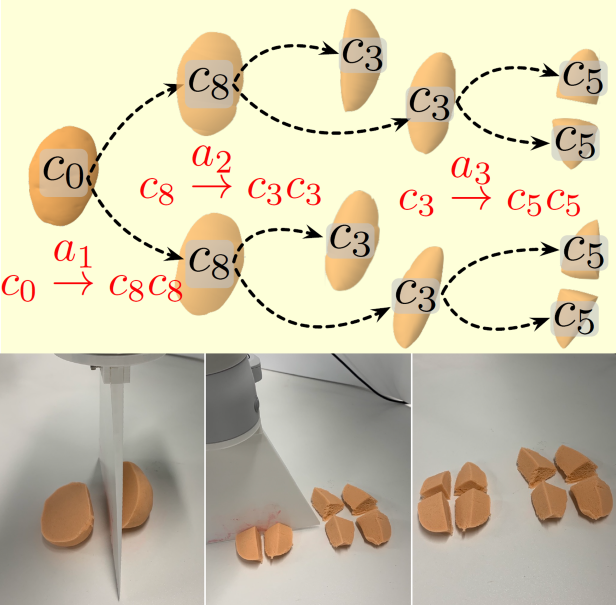
Zeyu Zhang*, Muzhi Han*, Baoxiong Jia, Ziyuan Jiao, Yixin Zhu, Song-Chun Zhu, Hangxin Liu * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023 Paper / Video (YouTube, bilibili) / Project Page An attributed stochastic grammar is proposed to model the process of object fragmentation during cutting, which abstracts the spatial arrangement of fragments as node variables and captures the causality of cutting actions based on the fragmentation of parts. |

|
Meng Wang*, Yao Su*, Hang Li, Jiarui Li, Jixiang Liang, Hangxin Liu * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023 Paper / Video (YouTube, bilibili) / Project Page We present a novel modular robot system capable of self-reconfiguration and achieving omnidirectional movements through magnetic docking for collaborative object transportation. Each robot in the system only equips a steerable omni wheel for navigation. |

|
Yao Su*, Jiarui Li*, Ziyuan Jiao*, Meng Wang, Chi Chu, Hang Li, Yixin Zhu, Hangxin Liu * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023 (Finalist--IROS Best Paper Award on Mobile Manipulation) Paper / Video (YouTube, bilibili) / Project Page Instead of one-step aerial manipulation tasks, we investigate the sequential manipulation planning problem of UAMs, which requires coordinated motions of the vehicle’s floating base, the manipulator, and the object being manipulated over a long horizon. |

|
Wanlin Li*, Meng Wang*, Jiarui Li, Yao Su✉, Devesh K. Jha, Xinyuan Qian, Kaspar Althoefer, Hangxin Liu✉ * equal contributors IEEE Robotics and Automation Letters (RA-L), 2023 Paper / Video (YouTube, bilibili) / Project Page We present an L3 F-TOUCH sensor that considerably enhances the three-axis force sensing capability of typical GelSight sensors, while being Lightweight, Low-cost, and supporting wireLess deplyment. |

|
Weiqi Wang*, Zihang Zhao*, Ziyuan Jiao*, Yixin Zhu, Song-Chun Zhu, Hangxin Liu * equal contributors IEEE International Conference on Robotics and Automation (ICRA), 2023 Paper / Video (YouTube, bilibili) / Project Page We present an optimization framework to redesign an indoor scene by rearranging the furniture within it, which maximizes free space for service robots to operate while preserving human's preference for scene layout. |

|
Muzhi Han*, Zeyu Zhang*, Ziyuan Jiao, Xu Xie, Yixin Zhu✉, Song-Chun Zhu, Hangxin Liu✉ * equal contributors International Journal of Computer Vision (IJCV), 2022 Paper / Project Page We rethink the problem of scene reconstruction from an embodied agent’s perspective. The objects within a reconstructed scene are segmented and replaced by part-based articulated CAD models to provide actionable information and afford finer-grained robot interactions. |
|
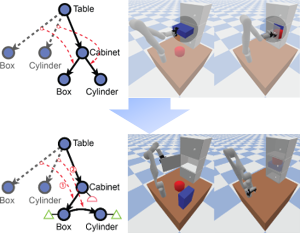
Ziyuan Jiao, Yida Niu, Zeyu Zhang, Song-Chun Zhu, Yixin Zhu, Hangxin Liu IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022 Paper / Video (YouTube, bilibili) / Project Page We devise a 3D scene graph representation to abstract scene layouts with succinct geometric information and valid robot-scene interactions, such that a valid task plan can be computed using graph editing distance between the initial and the final scene graph while effectively satisfying constraints in motion level. |

|
Yao Su*, Chi Chu*, Meng Wang, Jiarui Li, Liu Yang, Yixin Zhu, Hangxin Liu * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022 Paper / Video (YouTube, bilibili) / Project Page Leveraging the input redundancy in over-actuated UAVs, we tackle downwash effects between propellers with a novel control allocation framework that explores the entire allocation space for an optimal solution that reduces counteractions of airflows. |
|
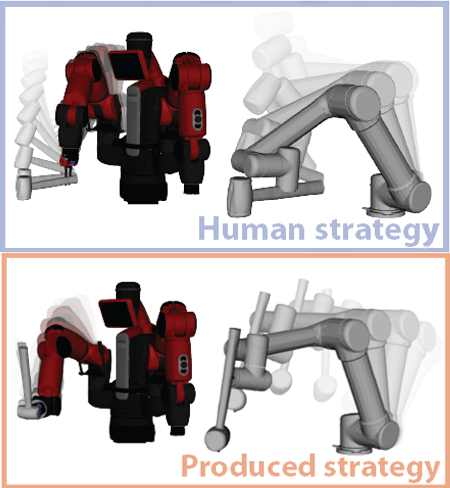
Zeyu Zhang*, Ziyuan Jiao*, Weiqi Wang, Yixin Zhu, Song-Chun Zhu, Hangxin Liu✉ * equal contributors IEEE Robotics and Automation Letters (RA-L+IROS), 2022 Paper / Video (vimeo, bilibili) Learning key physical properties of tool-uses from a FEM-based simulation and enacting those properties via an optimal control-based motion planning scheme to produce tool-use strategies drastically different from observations, but with the least joint efforts. |

|
Yao Su, Yuhong Jiang, Yixin Zhu, Hangxin Liu✉ IEEE Robotics and Automation Letters (RA-L+ICRA), 2022 Paper / Video (vimeo, bilibili) / Project Page A cooperative planning framework to generate optimal trajectories for a robot duo tethered by a flexible net to gather scattered objects spread in a large area. Implemented Model Reference Adaptive Control (MRAC) to handle unknown dynamics of carried payloads. |
|
Hangxin Liu, Yixin Zhu, Song-Chun Zhu Applied AI Letters, 2021 (DARPA XAI Speical Issue) Paper Given an interpretable And-Or-Graph knowledge representation, the proposed AR interface allows users to intuitively understand and supervise robot's behaviors, and interactively teach the robot with new actions. |
|
|
Ziyuan Jiao*, Zeyu Zhang*, Xin Jiang, David Han, Song-Chun Zhu, Yixin Zhu, Hangxin Liu * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021 Paper / Video / Code Constructing a Virtual Kinematic Chain (VKC) that readily consolidates the kinematics of the mobile base, the arm, and the object to be manipulated in mobile manipulations. |

|
Ziyuan Jiao*, Zeyu Zhang*, Weiqi Wang, David Han, Song-Chun Zhu, Yixin Zhu, Hangxin Liu * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021 Paper / Video / Code The VKC perspective is a simple yet effective method to improve task planning efficacy for mobile manipulation. |
|
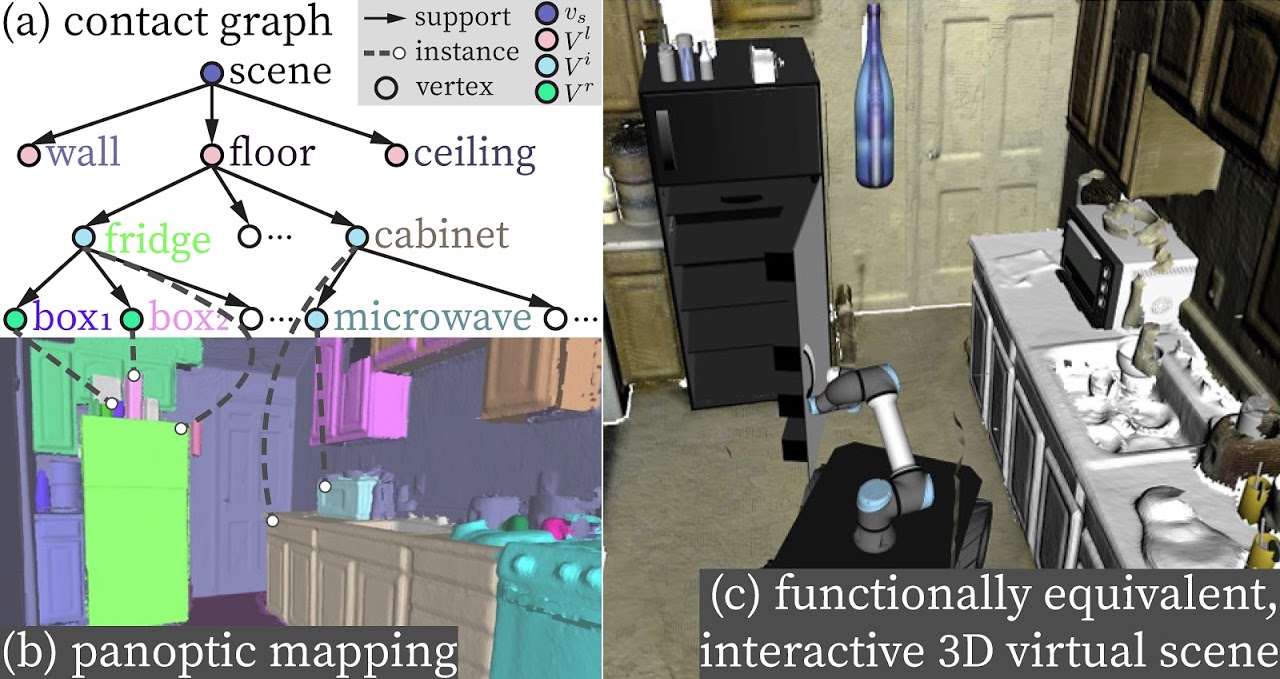
Muzhi Han*, Zeyu Zhang*, Ziyuan Jiao, Xu Xie, Yixin Zhu, Song-Chun Zhu, Hangxin Liu * equal contributors IEEE International Conference on Robotics and Automation (ICRA), 2021 Paper / Video / Code Reconstructing an interactive scene from RGB-D data stream by panoptic mapping and organizing object affordance and contextual relations by a graph-based scene representation. |

|
Shuwen Qiu*, Hangxin Liu*, Zeyu Zhang, Yixin Zhu, Song-Chun Zhu * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020 Paper / Video / Code / Presentation Physical robots can control and alter virtual objects in AR as an active agent and proactively interact with human agents, instead of purely passively executing received commands. |
|
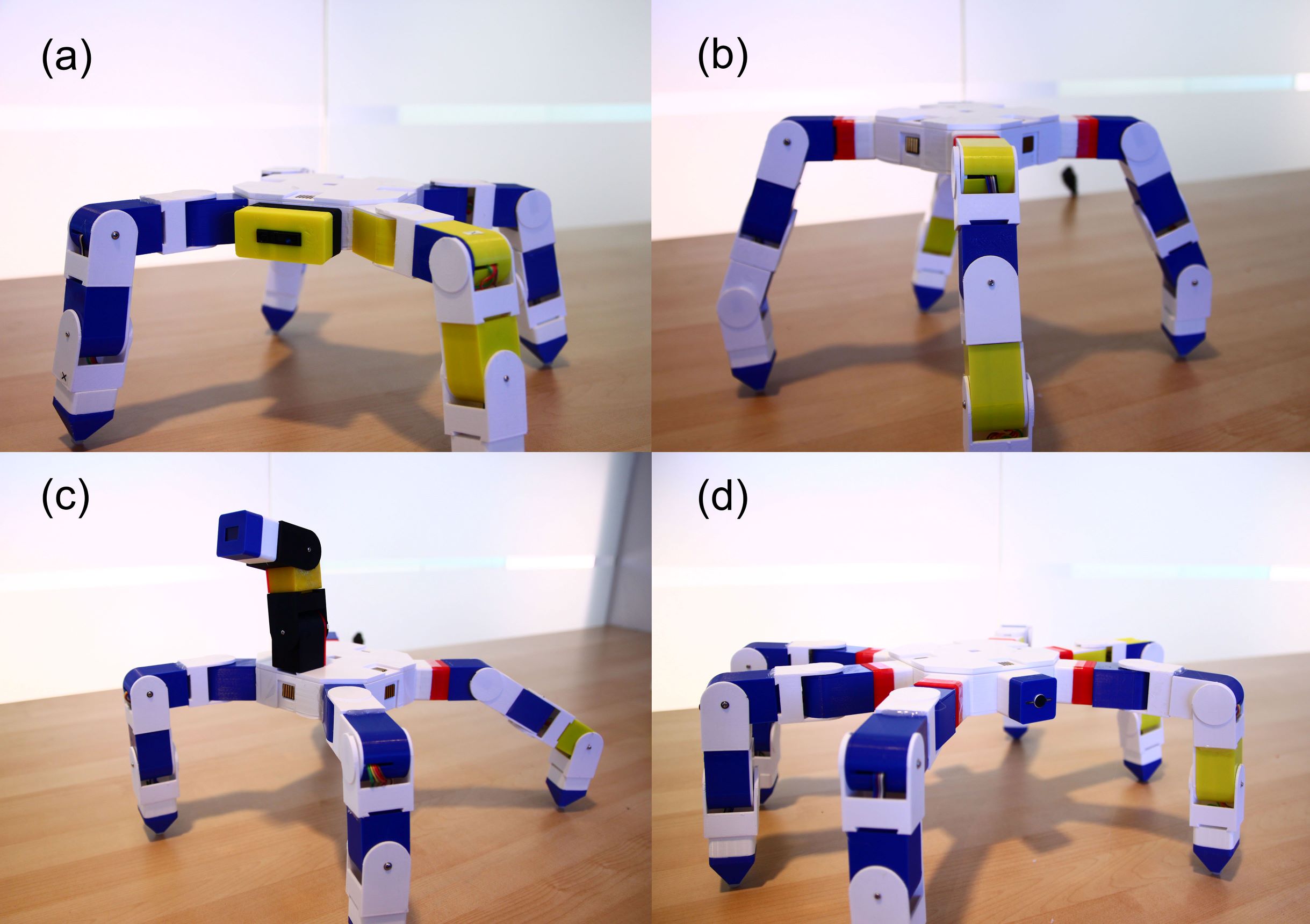
Meng Wang, Yao Su, Hangxin Liu, Yingqing Xu IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), 2020 Paper A modular robot system that allows non-expert users to build a multi-legged robot in various morphologies using a set of building blocks with sensors and actuators embedded. |
|
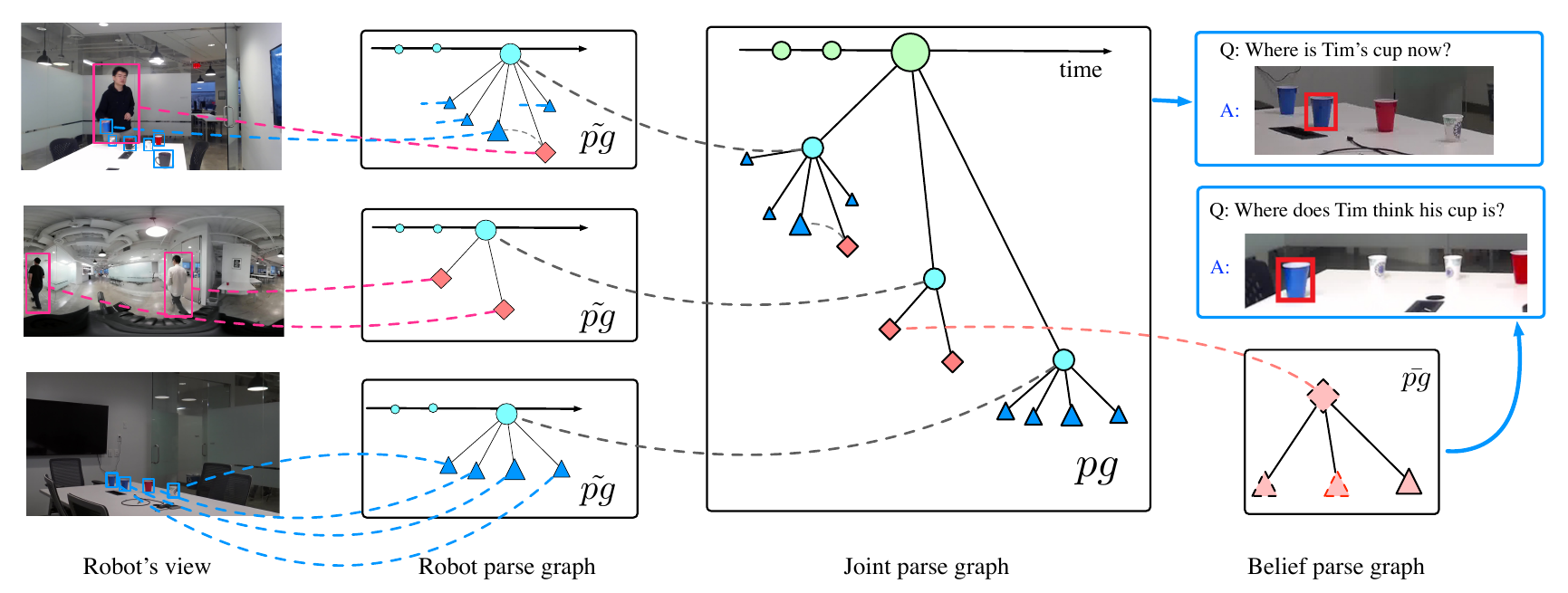
Tao Yuan, Hangxin Liu, Lifeng Fan, Zilong Zheng, Tao Gao, Yixin Zhu, Song-Chun Zhu IEEE International Conference on Robotics and Automation (ICRA), 2020 Paper / Video / Presentation A graphical model to unify the representation of object states, robot knowledge, and human (false-)beliefs. |
|
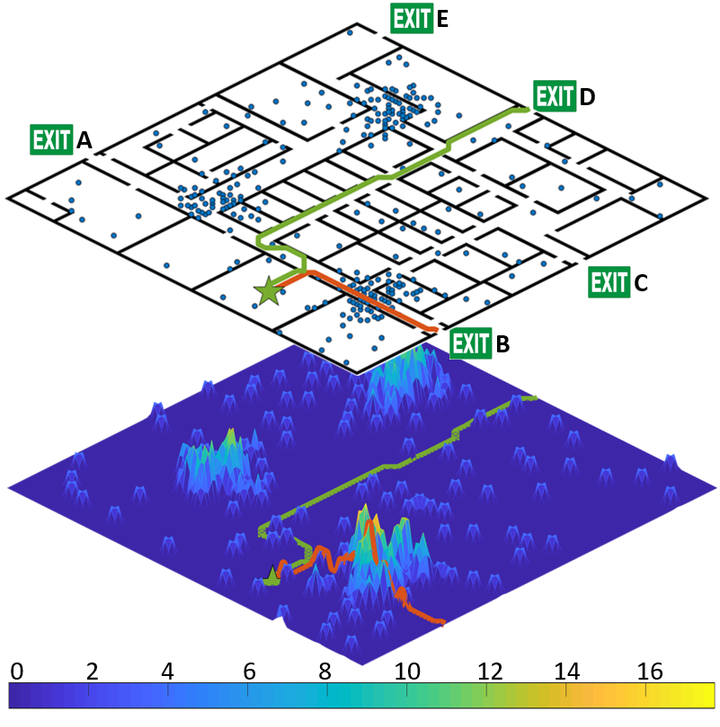
Zeyu Zhang, Hangxin Liu, Ziyuan Jiao, Yixin Zhu, Song-Chun Zhu IEEE International Conference on Robotics and Automation (ICRA), 2020 Paper / Video / Code / Presentation An AR-based indoor evacuation system with a congestion-aware routing solution. |
|
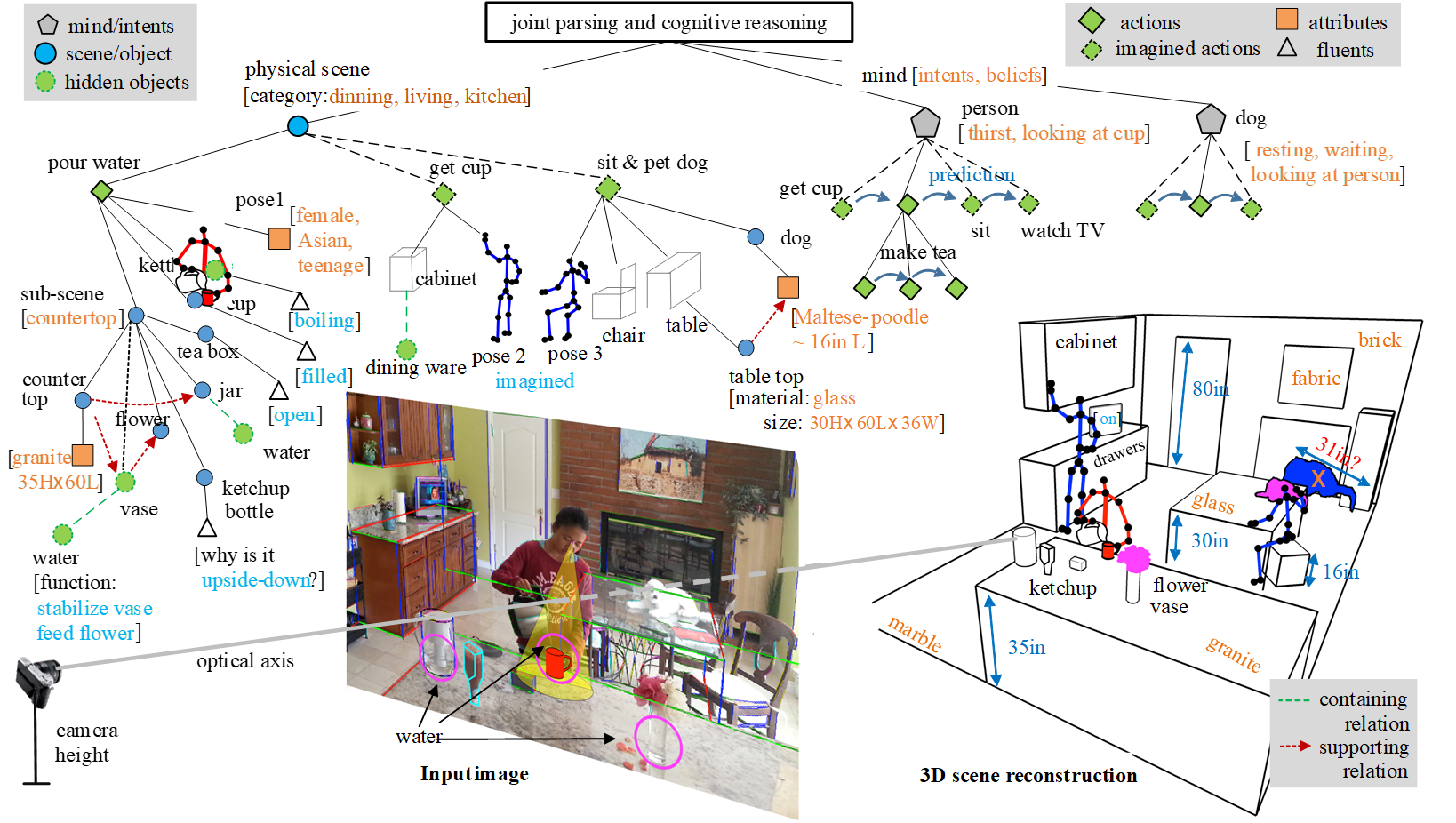
Yixin Zhu, Tao Gao, Lifeng Fan, Siyuan Huang, Mark Edmonds, Hangxin Liu, Feng Gao, Chi Zhang, Siyuan Qi, Ying Nian Wu, Joshua B. Tenenbaum, Song-Chun Zhu Engineering, 2020 Paper A comprehensive review on cognitive AI and visual commonsense (Functionality, Physics, Intension, Causality). |

|
Mark Edmonds*, Feng Gao*, Hangxin Liu*, Xu Xie*, Siyuan Qi, Brandon Rothrock, Yixin Zhu, Ying Nian Wu, Hongjing Lu, Song-Chun Zhu * equal contributors Science Robotics, 2019 Paper Learning multi-modal knowledge representation and fostering human trusts by producing explanations. |
|
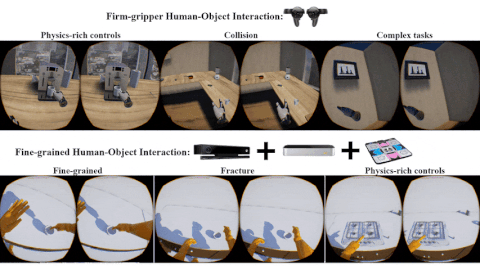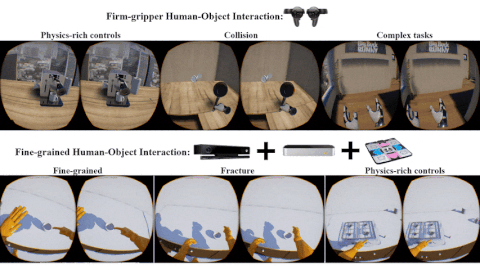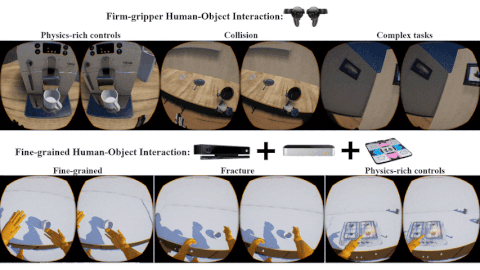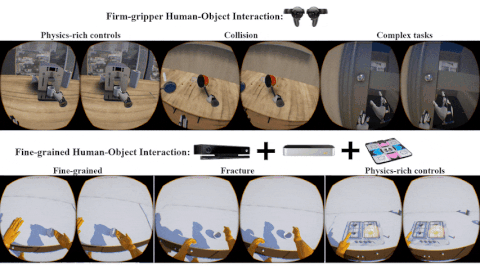
Xu Xie, Hangxin Liu, Zhenliang Zhang, Yuxing Qiu, Feng Gao, Siyuan Qi, Yixin Zhu, Song-Chun Zhu ACM Turing Celebration Conference - China (ACM TURC), 2019 Paper / Video / Code A testbed with fine-grained physical effects and realistic human-robot interactions for training embodied agents. |
|
Hangxin Liu*, Zeyu Zhang*, Yixin Zhu, Song-Chun Zhu * equal contributors IEEE International Conference on Robotics and Automation (ICRA), 2019 Paper / Video / Code Robot 'labels' received data by its own exploration and refines its predictive model on-the-fly. |
|
.

|
Hangxin Liu*, Zhenliang Zhang*, Xu Xie, Yixin Zhu, Yue Liu, Yongtian Wang, Song-Chun Zhu * equal contributors IEEE International Conference on Robotics and Automation (ICRA), 2019 Paper / Video / Code A data glove for natural human grasping activities in VR and for cost-effective grasping data collections. |

|
Hangxin Liu, Chi Zhang, Yixin Zhu, Chenfanfu Jiang, Song-Chun Zhu AAAI Conference on Artificial Intelligence (AAAI), 2019 Paper Learning functionally equivalent actions that produce similar effects instead of learning trajectory cues. |

|
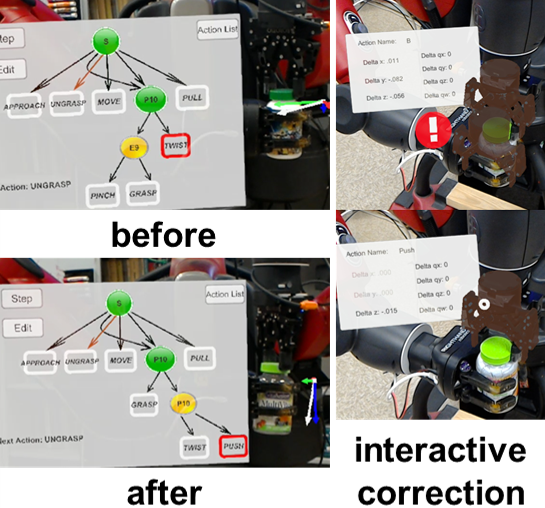
Hangxin Liu*, Yaofang Zhang*, Wenwen Si, Xu Xie, Yixin Zhu, Song-Chun Zhu * equal contributors IEEE International Conference on Robotics and Automation (ICRA), 2018 Paper / Video / Code An AR system for users to diagnose robor's problems, correct wrong behaviors, and add the corrections to the robot's knowledge. |
|
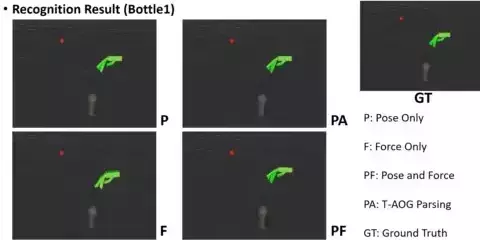
Xu Xie*, Hangxin Liu*, Mark Edmonds, Feng Gao, Siyuan Qi, Yixin Zhu, Brandon Rothrock, Song-Chun Zhu. * equal contributors IEEE International Conference on Robotics and Automation (ICRA), 2018 Paper / Video / Code An unsupervised learning approach for manipulation event segmentation and parsing using hand gestures and forces data. |
|
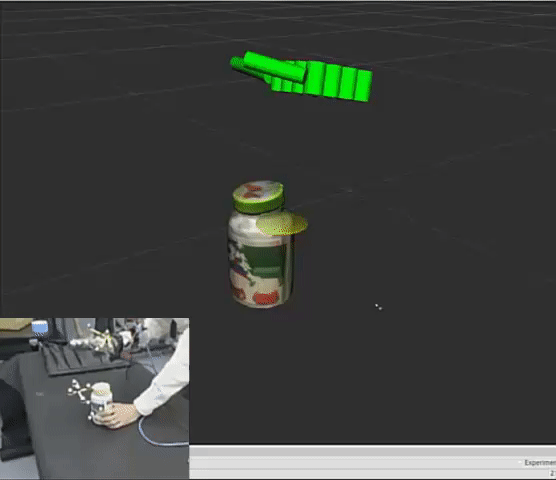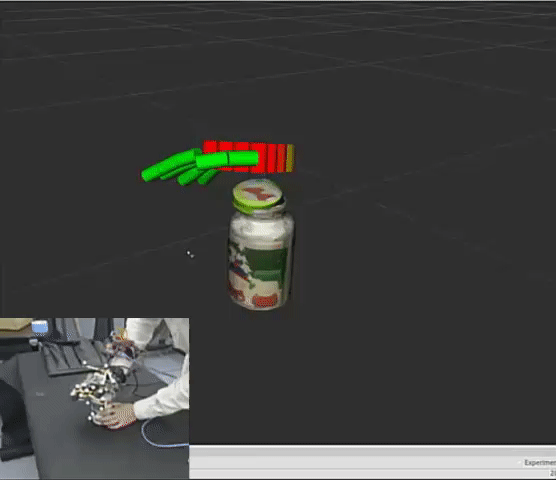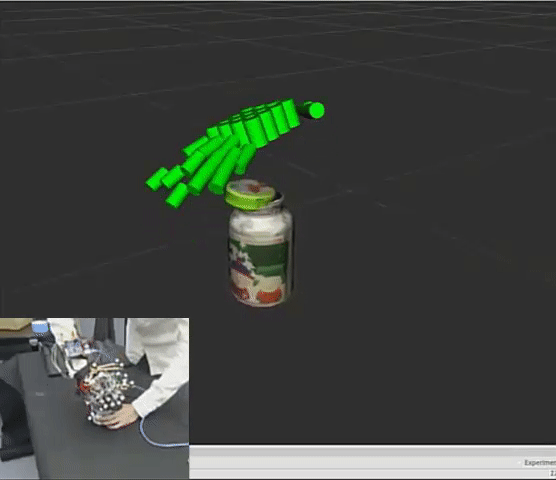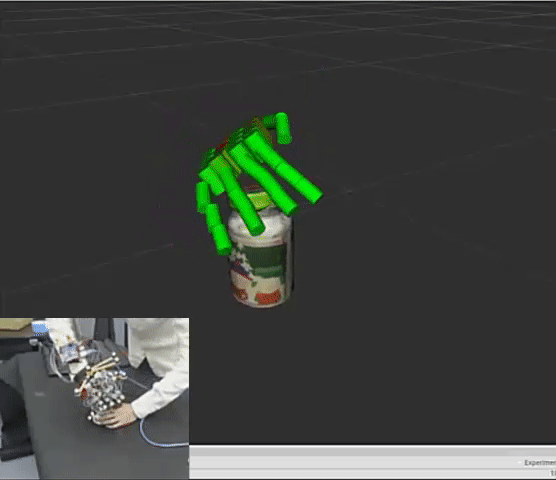
Hangxin Liu*, Xu Xie*, Matt Millar*, Mark Edmonds, Feng Gao, Yixin Zhu, Veronica Santos, Brandon Rothrock, Song-Chun Zhu. * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017 Paper / Code A easy-to-replicate glove-based system for real time collections of hand pose and force during fine manipulative actions. |

|
Mark Edmonds*, Feng Gao*, Xu Xie, Hangxin Liu, Siyuan Qi, Yixin Zhu, Brandon Rothrock, Song-Chun Zhu. * equal contributors IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017 Paper / Video / Code Learning an action planner through both a top-down stochastic grammar model (And-Or graph) and a bottom-up discriminative model from the observed poses and forces |

|
Yi Tian, Hangxin Liu, Tomonari Furukawa. SAE International Journal of Passenger Cars-Electronic and Electrical Systems, 2017 Paper
|
|
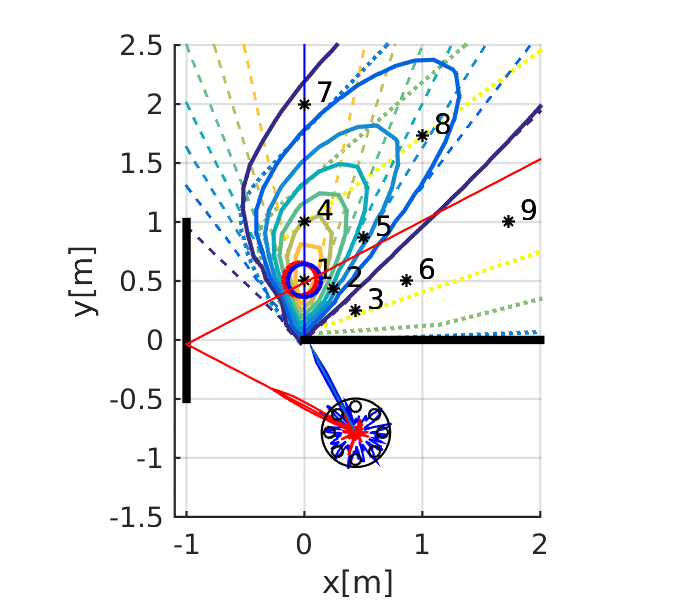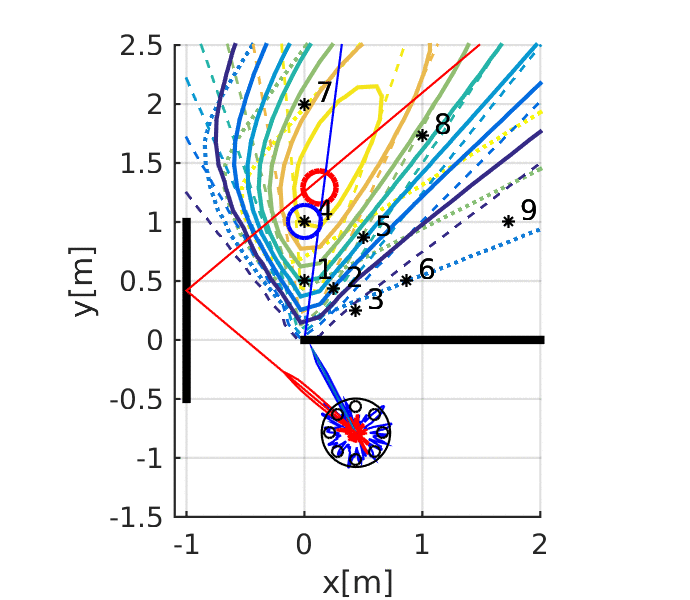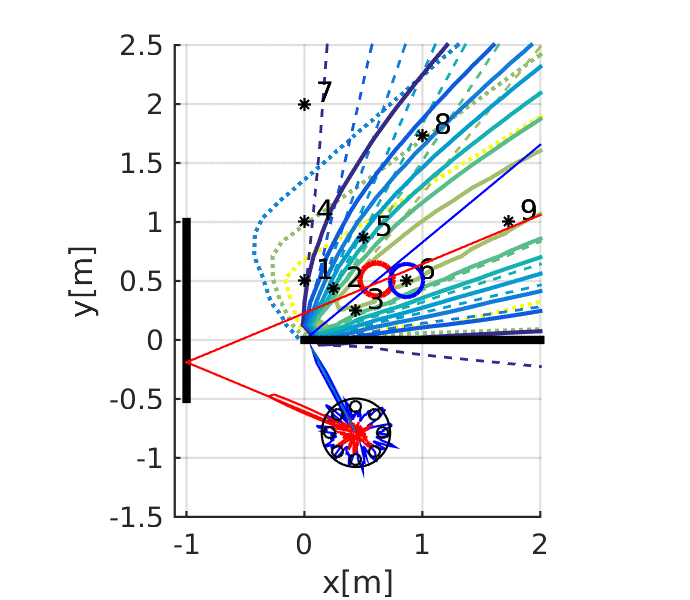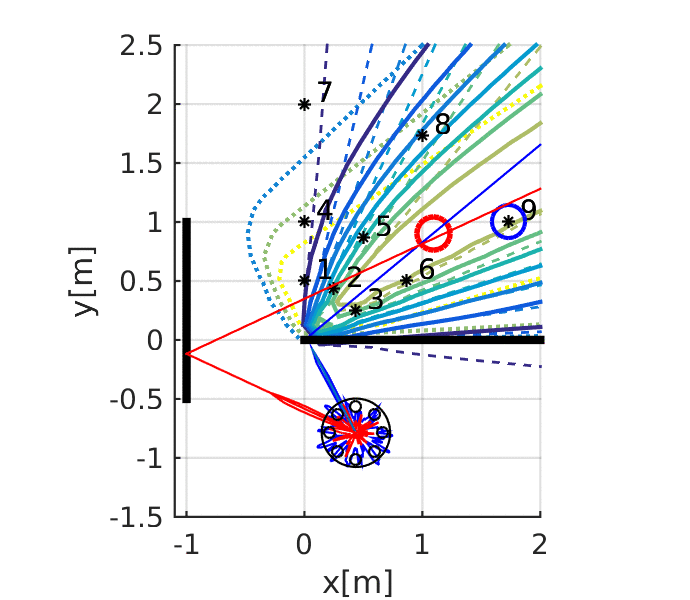
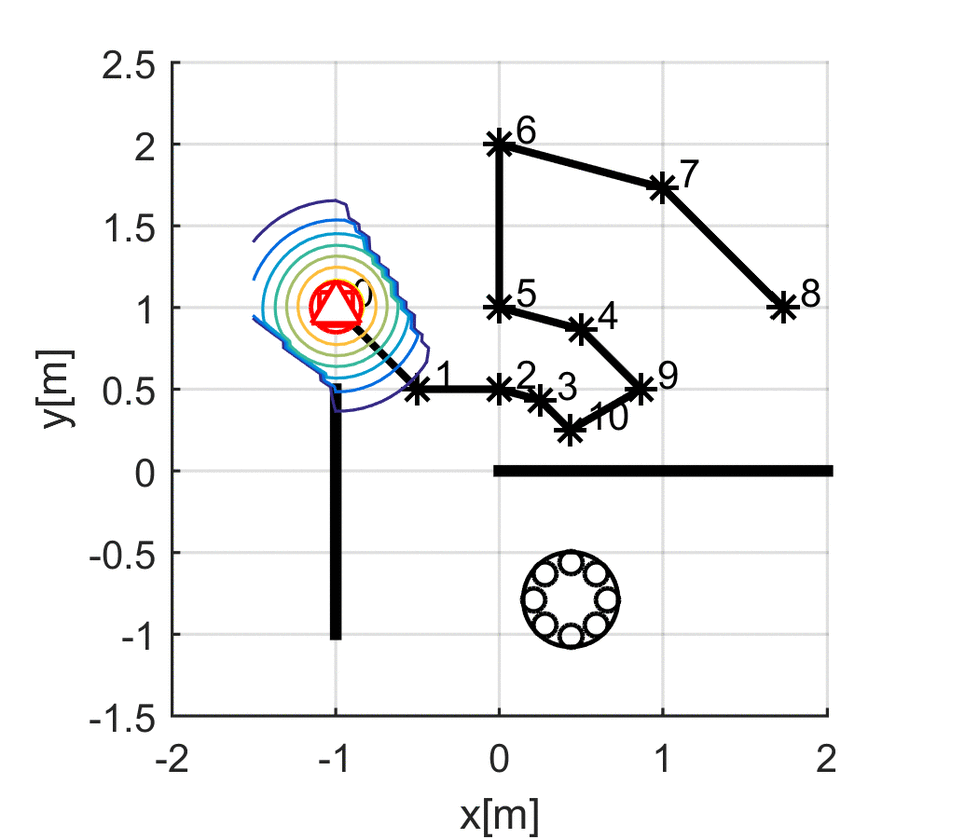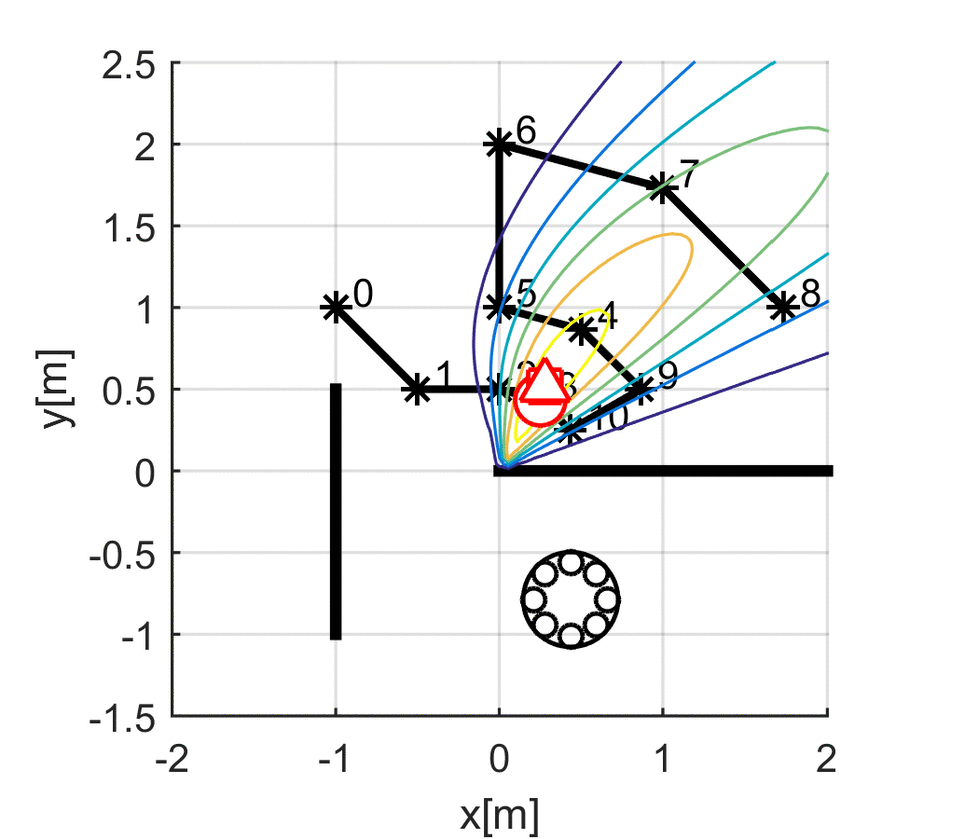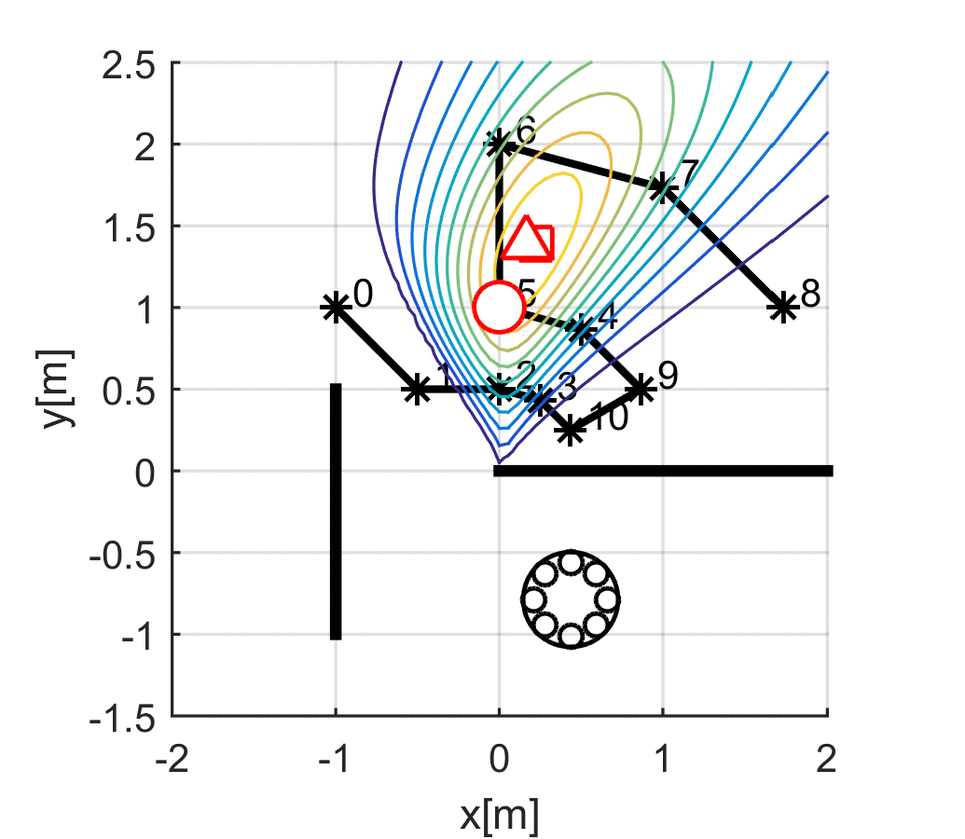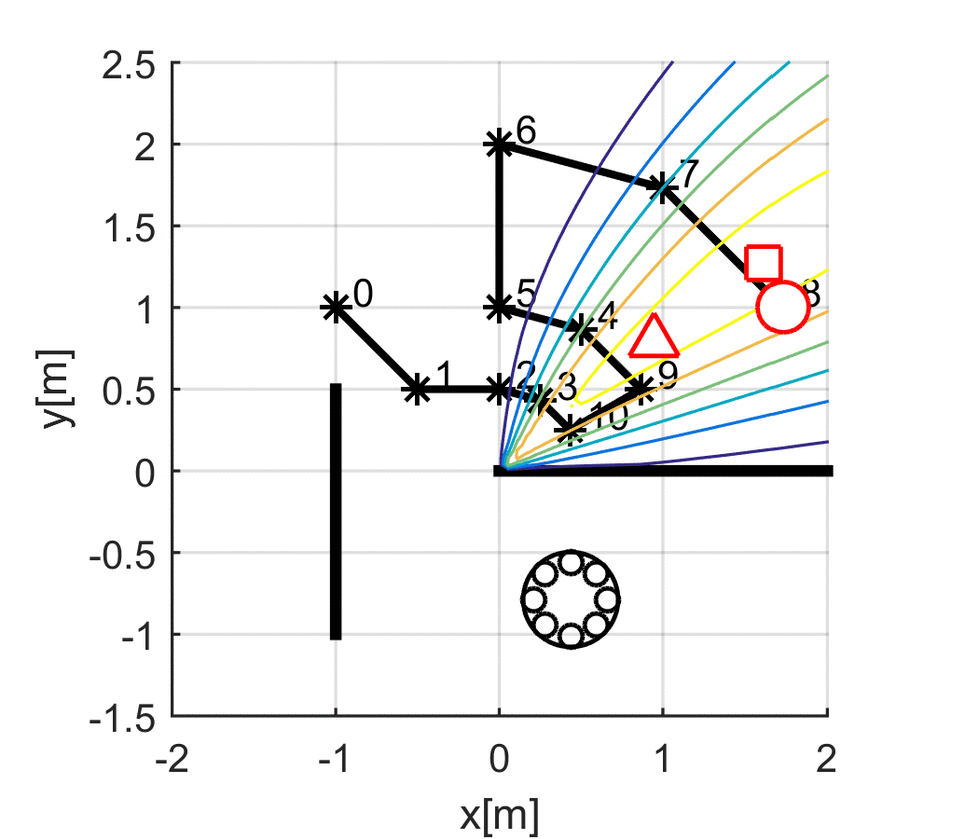
Kuya Takami, Hangxin Liu, Tomonari Furukawa, Makoto Kumon, Gamini Dissanayake. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2016 Paper
|
|
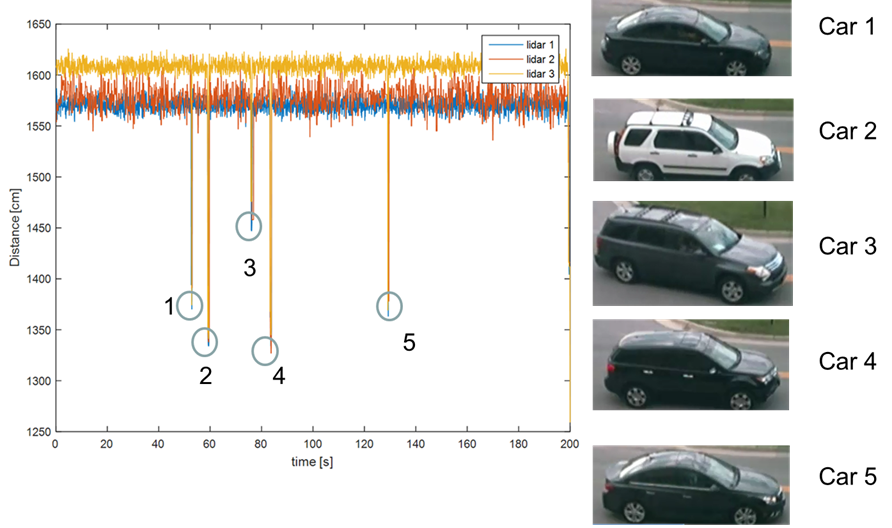
Hangxin Liu, Yi Tian, Tomonari Furukawa. ASME International Design Engineering Technical Conferences and Computers and Information in Engineering Conference (ASME IDETC), 2016 Paper
|
|
Kuya Takami, Hangxin Liu, Tomonari Furukawa, Makoto Kumon, Gamini Dissanayake. ISIF International Conference on Information Fusion (FUSION), 2016 Paper
|
|
Design and source code from Jon Barron's website |